
Retrieval-Augmented Generation (RAG) pipelines. #3
Explained for someone who wants to actually understand it.

Lecture III: Failure Modes in RAG Systems
(Engineered AI Compliance Series – Governance & Legal Professionals Edition)

RAG is not just search + LLM.
RAG is a fragile chain of epistemic trust with legal consequences at every link.
Key sections:
Why failure in RAG is epistemic not operational
Poisoned RAG, stale vectors, silent drift
Why these are worse than hallucination
Basic questions to ask (trust boundaries, versioning, reconstructability, drift detection, staleness prevention)
1. Why We Study Failure Before Optimization
Before we talk scale, latency, or accuracy, we need to answer a harder question: what does it actually mean for a RAG system to fail in a regulated environment?
In traditional software systems, failure is usually visible such as crashes, timeouts, or error codes. The system announces that something is wrong.
RAG systems fail differently.
The system continues to respond. The interface remains smooth. Tokens are generated fluently. From the outside, everything appears to be working.
But inside, the answer may no longer be grounded in the right documents, aligned with current policy, or legally defensible.
Their most dangerous failures are epistemic rather than operational.
This is why failure modes in RAG systems matter disproportionately in regulated and compliance-sensitive environments. The primary risk is not downtime.
The primary risk is the production of plausible misrepresentation: outputs that appear authoritative, internally grounded, and compliant, while silently violating governance, policy, or legal constraints.
That’s why we study failure modes not as rare bugs, but as structural properties of the RAG architecture itself.
Because the system can produce legally actionable statements while appearing operationally correct.
In regulated environments, a RAG system can be fully functional while simultaneously producing answers that create audit failure, contractual breach, or regulatory exposure.
For governance/legal professionals who are not engineers, that perceptual shift is important. It’s the difference between having chatbot and having a vector-retrieval-mediated representation engine whose semantic integrity determines liability.
For that we need to understand better what this pipeline consist of.
2. The RAG Pipeline Components
To understand failure, we must briefly restate the structure of the system and the trust assumptions embedded at each stage.
A standard RAG pipeline is a chain consisting the following components:
Source documents (your corpus)
assumes that included documents are legitimate, authorized, and within the intended scope of use.Embedding model (turn those documents into vectors)
assumes that semantic similarity preserves meaning relevant to policy, law, or instruction.Vector database (stores, searches and indexes those vectors)
assumes stable indexing, correct versioning, and integrity between stored vectors and their source documents.Retrieval (finds similar vectors for a query)
assumes that similarity corresponds to relevance, priority, and applicability.Generation (feeds retrieved text to LLM)
assumes that retrieved context is authoritative and safe to condition on.
Trust in a RAG system is cumulative. If an error or misalignment is introduced early during ingestion, embedding, or indexing, it propagates forward silently. By the time text is generated, the system has no native awareness that its epistemic foundation has shifted.
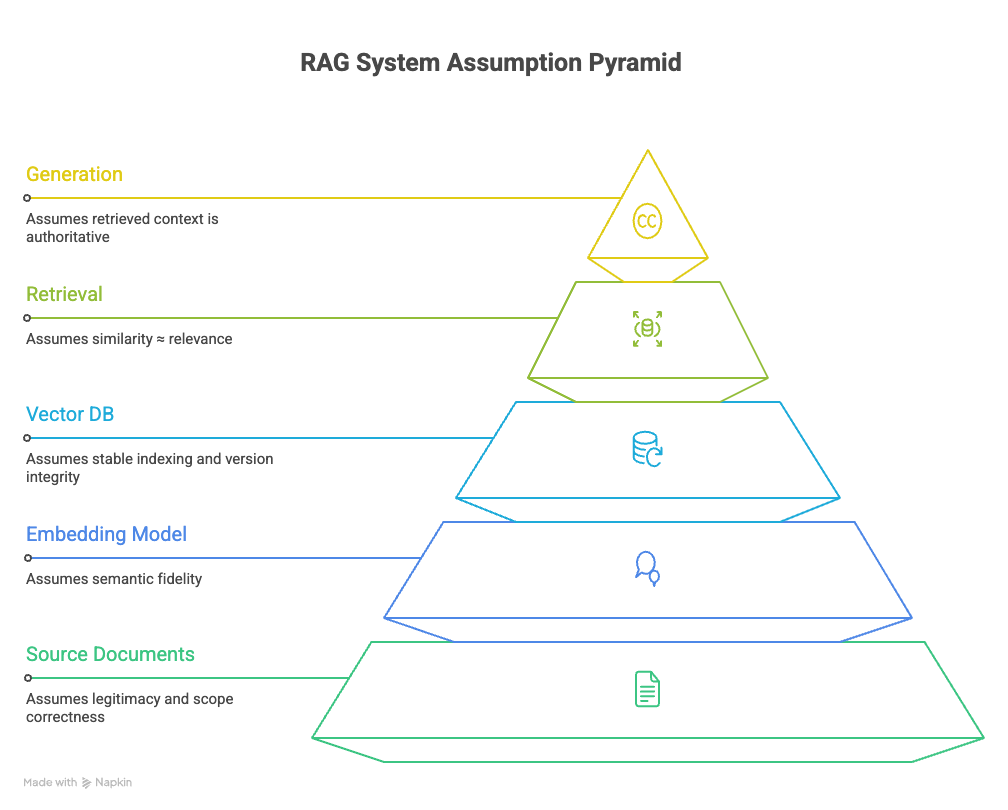
Failure in RAG systems is rarely localized. It is typically distributed across components and delayed in its manifestation.
When a RAG system fails, it rarely does so uniformly across the pipeline. Failure typically begins at the earliest trust boundary: the moment content is admitted into the corpus and treated as eligible for retrieval.
Now that we understand the fragile chain, let's look at exactly how it breaks. The first failure mode begins at the moment data enters the system.
What is Poisoned RAG?
→ What if the content should never have been there?
What it is
Malicious, outdated, or untrusted content gets into the retrieval corpus and is later retrieved and presented to the language model as authoritative context.
Why it’s bad for compliance
What matters here is not only what content is ingested but also how retrieval works.
Recall that vector retrieval is based on semantic similarity, not provenance. The system does not ask whether a document is official, recent, or authorized. It asks whether the document’s vector is close to the query vector in high-dimensional space.
An attacker does not need to override/hack your system. They only need to make their content semantically attractive to likely queries.
This can occur through:
Injected documentation in internal knowledge bases
User-generated content indexed without strong trust boundaries
External sources pulled into the corpus without validation
Legacy documents that were never intended to be used as live reference
Once embedded, poisoned content is indistinguishable from legitimate content at retrieval time unless explicit controls exist.
From a legal and compliance perspective, this is critical: the system may generate outputs that appear to be grounded in internal documentation but are, in fact, influenced by unvetted or adversarial material.
The model does not know it is lying. It is simply completing a task based on what it was given.
Scenario
A mid-sized fintech routes user complaints into the knowledge base without review → model starts recommending non-compliant workarounds in customer responses.
Legal side
Output looks grounded in internal knowledge. Regulators/courts see plausible sourcing. You have plausible misrepresentation - the worst kind of liability.
Action
Ask your engineers today:
What trust boundaries exist between user content and the retrieval corpus?
Is there provenance filtering or human-only namespaces?
Can you block or de-rank external/low-trust sources at retrieval time?
Poisoned RAG shows how authority can be corrupted through content inclusion. Yet even in the absence of untrusted or adversarial material, RAG systems remain vulnerable to a quieter failure mode.
Because retrieval operates on embedded representations rather than live documents, every RAG system embeds an implicit assumption about time. Poisoned RAG reflects a failure of what the system is allowed to know. Staleness reflects a failure of when that knowledge remains valid.
The two are structurally distinct but sequential.
What are Stale Vectors?
→ What if the content used to be correct, but isn’t anymore?
What it is
Source documents change (policy updated, regulation revised), but the vectors in the database stay old.
This is not a bug or a scaling problem. It is rather an operational reality in any organization where:
– Policies are updated
– Legal interpretations evolve
– Product behavior changes
– Regulatory guidance is revised
Why it’s bad for compliance
If a document is modified but its corresponding vector is not re-embedded and re-indexed, the system continues to retrieve an outdated semantic representation.
It simply means: The document system says one thing. The retrieval system remembers another. The model cites the old semantic meaning, even if the text was corrected elsewhere.
As a result, the model may retrieve passages that no longer correspond to the current meaning of a policy while presenting them as authoritative context.
From a compliance standpoint, this creates a dangerous asymmetry: the system appears current but is semantically frozen in the past.
Unlike traditional document management systems, vector databases do not naturally expose this mismatch. There is no visible version conflict, warning, or access control signal unless the system is explicitly designed to surface one.
Scenario
Healthcare provider updates consent language in January. Vectors aren’t re-embedded until March. In February, chatbot cites old consent rules → potential GDPR violation.
Legal side
System appears current (text is updated), but is semantically outdated. Audit shows mismatch. DPIA claims are unverifiable.
Action
Ask:
Do you version embeddings alongside document versions?
Is there an automated re-indexing trigger on policy/legal updates?
Can you prove which vector version was used for any past output?
At first glance, staleness appears to be a solvable synchronization problem: update documents, re-embed vectors, and restore alignment. But this assumption hides a deeper fragility.
Even when documents are current and embeddings are refreshed, RAG systems are not static. Their behavior evolves as models change, retrieval landscapes shift, and preprocessing decisions accumulate over time. At that point, failure no longer stems from outdated content, but from the system’s changing relationship to its own knowledge.
That brings us to the silent drift.
What is Silent Drift?
→ What if nothing is wrong in isolation, but the system itself has changed?
What is it
The system’s behavior changes gradually without a single obvious trigger/point of failure.
There are several sources:
Embedding model upgrades
Chunking/preprocessing changes
LLM provider updates
Gradual accumulation of new documents that shifts the retrieval landscape
Why it’s bad for compliance
Each change may be defensible in isolation. Together, they alter what the system retrieves, how it prioritizes sources, and which documents dominate responses.
Crucially, drift does not require bad intent. It is often the result of normal maintenance and improvement.
The legal problem is not that the system evolves. The problem is that no one can later reconstruct what the system believed at a given point in time.
So,
No one can reconstruct what the system believed (!) six months ago.
Audit question: Which documents were retrieved for this query on 15 July 2025?
In many RAG deployments, the honest answer is no.
If a system produced an answer six months ago, can you demonstrate:
Which documents were eligible for retrieval?
Which vectors were closest to the query?
Which embedding model version was used?
Which generation model conditioned the output?
Legal exposure
No traceability = no defensibility.
EU AI Act high-risk systems require exactly this kind of auditability.
Immediate action
Ask:
“Can you reconstruct the exact retrieval set for any past output?”
“Do you snapshot embedding model versions and corpus state?”
“Is there drift detection or periodic re-validation?”
This is not a bug.
We cannot frame all of these issues as variations of hallucination. That is a mistake.
Hallucination is visible error: the model invents content that clearly does not exist. It’s easy to flag.
RAG failure modes are more dangerous precisely because they produce plausible, sourced-looking answers. The system appears to be citing internal knowledge.
In regulated environments, the difference matters. An obviously incorrect answer is easier to flag than a subtly outdated or poisoned one.
The compliance risk is false grounding.
At this point, we are not yet designing controls. We are learning to recognize where control must exist.
What should already be clear is that:
Vector databases are not passive storage layers
Retrieval is a policy-relevant operation
Embeddings are not neutral representations
Time and versioning are legal concerns, not merely technical ones
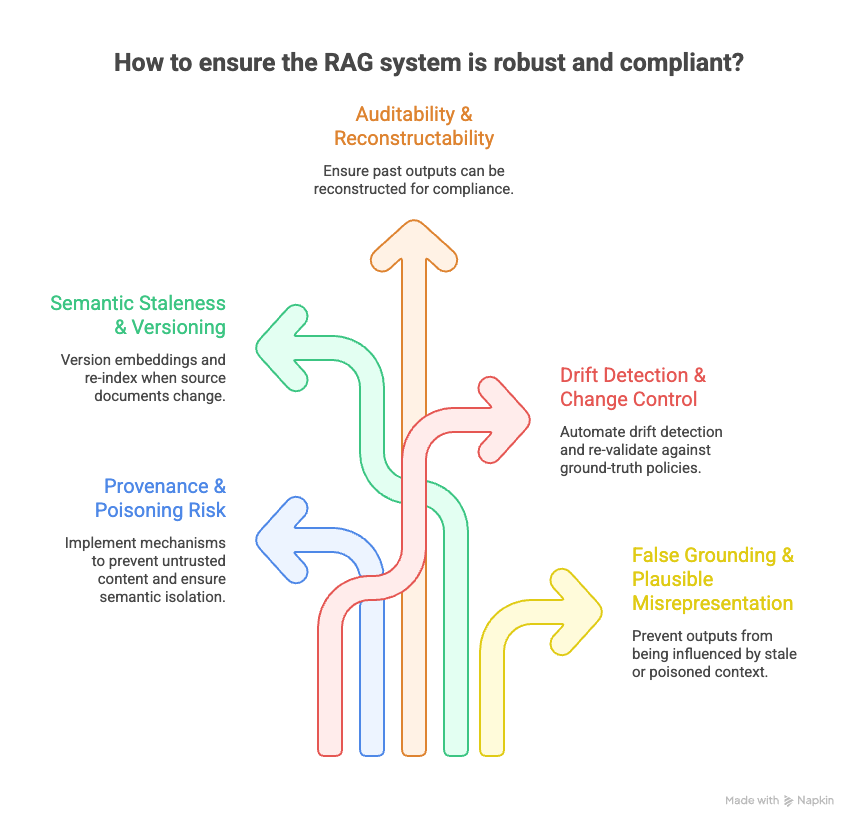
5 Questions Legal Product Architects Should Force Their Teams / Vendors to Answer
This is where legal product architects must step in — not to code, but to demand architectural visibility and accountability before the system ships. These five questions target the highest-leverage pinpoints where governance fails if left unaddressed.
Provenance & Poisoning Risk “What mechanisms prevent untrusted or adversarial content from being retrieved as authoritative context? Can you prove semantic isolation between user-generated input and core policy/knowledge corpus?”
Semantic Staleness & Versioning “How are embeddings versioned and re-indexed when source documents or policies change? Can you demonstrate that the retrieved semantics match the current legal/policy state at any point in time?”
Auditability & Reconstructability “For any past output, can you reconstruct the exact retrieval set, vector versions, embedding model version, and generation snapshot used? If not, how do you defend compliance claims in an audit or litigation?”
Drift Detection & Change Control “What automated controls detect silent semantic drift caused by model upgrades, chunking changes, or corpus growth? How often is the system re-validated against ground-truth policies?”
False Grounding & Plausible Misrepresentation “How do you ensure outputs that appear ‘grounded’ in internal knowledge are not influenced by stale, poisoned, or drifted context? What runtime checks or observability exist to catch false grounding before it reaches users?”
These questions are not technical solely, they are legal exposure questions. If the answers are vague or absent, the risk is already material. Use them in vendor RFPs, engineering syncs, DPIAs, and board-level risk reviews.
Quick Checklist – What to Ask Your Engineers Tomorrow
Before Lecture IV (design controls), give your team this short list:
Are there trust boundaries between user content and the retrieval corpus?
Why it matters
User-generated content (complaints, support tickets, chat logs, uploaded files) is inherently untrusted — it can contain misinformation, adversarial inputs, or even deliberate poisoning. If there is no architectural separation (e.g., namespaces, content filters, de-ranking rules, or hard blocks), user content can end up retrieved and treated as authoritative knowledge. The model then generates answers that look “grounded in internal data” but are actually grounded in whatever a user once wrote.Legal exposure if “no” or “we don’t know”
Plausible misrepresentation in customer-facing or regulated outputs (e.g., advice, disclosures, policy explanations).
GDPR Art. 5(1)(d) integrity/accuracy violation (system outputs inaccurate facts as “official”).
EU AI Act high-risk system non-conformity (lack of data governance controls).
Tort/contractual liability if users rely on poisoned advice.
Worst case: class-action or regulatory probe showing the system presented unvetted user content as company knowledge.
Fintech/insurtech chatbots have been caught recommending non-compliant products because user complaints were indexed without review.
Do you version embeddings alongside document versions?
Why it matters
Policies, legal interpretations, terms of service, consent language, and regulatory references change frequently. If the text is updated in the document store but the vector representation stays old, the model retrieves outdated semantic meaning. The system looks current (text is updated), but behaves as if frozen in the past.Legal exposure if “no” or “we don’t know”
False grounding in audits: system cites semantic version of a policy that no longer exists.
GDPR Art. 5(1)(d) inaccuracy + Art. 17 erasure inconsistencies (old semantics survive deletion).
EU AI Act data governance failure (high-risk systems must ensure data quality over time).
Contractual breach if customer-facing outputs rely on superseded terms.
Healthcare providers updating consent forms but forgetting to re-embed → chatbot cites old consent rules for months.
Can you reconstruct the exact retrieval set for any past output?
Why it matters
In litigation, regulatory inquiries, or internal investigations, you will be asked: “What information was available to the system when it generated this response?” If you cannot prove which documents/vectors were retrieved, which embedding model was active, and which LLM version conditioned the output, you cannot defend the response.Legal exposure if “no” or “we don’t know”
Complete loss of defensibility in audits or court.
EU AI Act Art. 13 transparency and Art. 12 record-keeping violations (high-risk systems must enable traceability).
Inability to respond to DSARs or litigation discovery requests.
Presumption of non-compliance when evidence cannot be produced.
Financial regulators increasingly demand “reconstruction of decision context” in AI-assisted processes.
Is there drift detection or periodic semantic re-validation?
Why it matters
Embedding models, chunking logic, LLM providers, and corpus composition change over time (often silently). These changes shift what the system retrieves and how it ranks sources — without any single “break” moment. Without detection, the system’s behavior drifts gradually, and no one notices until an audit or complaint.Legal exposure if “no” or “we don’t know”
Undetectable non-conformity with policies or regulations over time.
Failure to maintain “ongoing conformity assessment” under EU AI Act.
Inability to prove stability of outputs for compliance reporting or liability defense.
Many enterprise deployments have seen drift after provider updates (e.g., OpenAI model swaps) without realizing it until customer complaints surface.
How do you prevent semantic staleness when policies change?
Why it matters
This is the operationalization of question 2. Even if you version embeddings, if there is no automated trigger to re-embed on policy/legal updates, staleness comes in and manual re-indexing is not scalable or reliable.Legal exposure if “no” or “we don’t know”
Same as stale vectors, but more likely to occur in practice (manual processes fail).
Breach of data governance obligations (EU AI Act, GDPR Art. 25 data protection by design).
Inability to demonstrate “timely update” in response to regulatory changes.
Compliance teams update a policy document, assume IT will handle re-indexing — IT forgets or delays → model cites old version for weeks/months.
Next Lecture
In the next lecture, we will move to design: trust boundaries, version semantics, and auditability at the level of the RAG pipeline itself.
Versioned embeddings & semantic versioning
Retrieval-time provenance & trust scoring
Immutable audit trails & reconstruction guarantees
Architectural trust boundaries at ingestion